There is a lot of confusion and misunderstanding about aliasing and moiré. So I’ve thrown together this article to try and explain whats going on and what you can (or can’t) do about it.
Sony’s FS700, F5 and F55 cameras all have 4K sensors. They also have the ability to shoot 4K raw as well as 2K raw when using Sony’s R5 raw recorder. The FS700 will also be able to shoot 2K raw to the Convergent Design Odyssey. At 4K these cameras have near zero aliasing, at 2K there is the risk of seeing noticeable amounts of aliasing.
One key concept to understand from the outset is that when you are working with raw the signal out of the camera comes more or less directly from the sensor. When shooting non raw then the output is derived from the full sensor plus a lot of extra very complex signal processing.
First of all lets look at what aliasing is and what causes it.
Aliasing shows up in images in different ways. One common effect is a rainbow of colours across a fine repeating pattern, this is called moiré. Another artefact could be lines and edges that are just a little off horizontal or vertical appearing to have stepped or jagged edges, sometimes referred to as “jaggies”.
But what causes this and why is there an issue at 2K but not at 4K with these cameras?
Lets imagine we are going to shoot a test pattern that looks like this:

And lets assume we are using a bayer sensor such as the one in the FS700, F5 or F55 that has a pixel arrangement like this, although it’s worth noting that aliasing can occur with any type of sensor pattern or even a 3 chip design:

Now lets see what happens if we shoot our test pattern so that the stripes of the pattern line up with the pixels on the sensor. The top of the graphic below represents the pattern or image being filmed, the middle is the sensor pixels and the bottom is the output from the green pixels of the sensor:

As we can see each green pixel “see’s” either a white line or a black line and so the output is a series of black and white lines. Everything looks just fine… or is it? What happens if we move the test pattern or move the camera just a little bit. What if the camera is just a tiny bit wobbly on the tripod? What if this isn’t a test pattern but a striped or checked shirt and the person we are shooting is moving around? In the image below the pattern we are filming has been shifted to the left by a small amount.
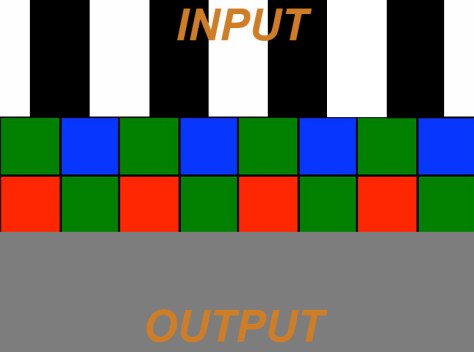
Now look at the output, it’s nothing but grey, the black and white pattern has gone. Why? Simply because the green pixels are now seeing half of a white bar and half of a black bar. Half white plus half black equals grey, so every pixel see’s grey. If we were to slowly pan the camera across this pattern then the output would alternate between black and white lines when the bars and pixels line up and grey when they don’t. This is aliasing at work. Imagine the shot is of a person with a checked shirt, as the person moves about the shirt will alternate between being patterned and being grey. As the shirt will be not be perfectly flat and even, different parts of the shirt will go in and out of sync with the pixels so some parts will be grey, some patterned, it will look blotchy. A similar thing will be happening with any colours, as the red and blue pixels will sometimes see the pattern at other times not, so the colours will flicker and produce strange patterns, this is the moiré that can look like a rainbow of colours.
So what can be done to stop this?
Well what’s done in the majority of professional level cameras is to add a special filter in front of the sensor called an optical low pass filter (OPLF). This filter works by significantly reducing the contrast of the image falling on the sensor at resolutions approaching the pixel resolution so that the scenario above cannot occur. Basically the image falling on the sensor is blurred a little so that the pixels can never see only black or only white. This way we won’t get flickering between black & white and then grey if there is any movement. The downside to this is that it does mean that some contrast and resolution will be lost, but this is better than having flickery jaggies and rainbow moiré. In effect the OLPF is a type of de-focusing filter (for the techies out there it is usually something called a birefringent filtre). The design of the OLPF is a trade off between how much aliasing is acceptable and how much resolution loss is acceptable. The OLPF cut-off isn’t instant, it’s a sharp but gradual cut-off that starts somewhere lower than the sensor resolution, so there is some undesirable but unavoidable contrast loss on fine details. The OLPF will be optimised for a specific pixel size and thus image resolution, but it’s a compromise. In a 4K camera the OLPF will start reducing the resolution/contrast before it gets to 4K.
(As an aside, this is one of the reasons why shooting with a 4K camera can result in better HD, because the OLPF in an HD camera cuts contrast as we approach HD, so the HD is never as sharp and contrasty as perhaps it could be. But shoot at 4K and down-convert and you can get sharper, higher contrast HD).
So that’s how we prevent aliasing, but what’s that got to do with 2K on the FS700, F5 and F55?
Well the problem is this, when shooting 2K raw or in the high speed raw modes Sony are reading out the sensor in a way that creates a larger “virtual” pixel. This almost certainly has to be done for the high speed modes to reduce the amount of data that needs to be transferred from the sensor and into the cameras processing and recording circuits when using high frame rates. I don’t know exactly how Sony are doing this but it might be something like my sketch below:

So instead of reading individual pixels, Sony are probably reading groups of pixels together to create a 2K bayer image. This creates larger virtual pixels and in effect turns the sensor into a 2k sensor. It is probably done on the sensor during the read out process (possibly simply by addressing 4 pixels at the same time instead of just one) and this makes high speed continuous shooting possible without overheating or overload as there is far less data to read out.
But, now the standard OLPF which is designed around the small 4K isn’t really doing anything because in effect the new “virtual” pixels are now much larger than the original 4K pixels the OLPF was designed around. The standard OLPF cuts off at 4K so it isn’t having any effect at 2K, so a 2K resolution pattern can fall directly on our 2K virtual bayer pixels and you will get aliasing. (There’s a clue in the filter name: optical LOW PASS filter, so it will PASS any signals that are LOWer than the cut off. If the cut off is 4K, then 2K will be passed as this is lower than 4K, but as the sensor is now in effect a 2K sensor we now need a 2K cut off).
On the FS700 there isn’t (at the moment at least) a great deal you can do about this. But on the F5 and F55 cameras Sony have made the OLPF replaceable. By loosening one screw the 4K OLPF can be swapped out with a 2K OLPF in just a few seconds. The 2K OLPF will control aliasing at 2K and high speed and in addition it can be used if you want a softer look at 4K. The contrast/resolution reduction the filter introduces at 2K will give you a softer “creamier” look at 4K which might be nice for cosmetic, fashion, period drama or other similar shoots.

Fs700 owners wanting to shoot 2K raw will have to look at adding a little bit of diffusion to their lenses. Perhaps a low contrast filter will help or a net or stocking over the front of the lens to add some diffusion will work to slightly soften the image and prevent aliasing. Maybe someone will bring out an OLPF that can be fitted between the lens and camera body, but for the time being to prevent aliasing on the FS700 you need to soften, defocus or blur the image a little to prevent the camera resolving detail above 2K. Maybe using a soft lens will work or just very slightly de-focussing the image.
But why don’t I get aliasing when I shoot HD?
Well all these cameras use the full 4K sensor when shooting HD. All the pixels are used and read out as individual pixels. This 4K signal is then de-bayered into a conventional 4K video signal (NOT bayer). This 4K (non raw) video will not have any significant aliasing as the OLPF is 4K and the derived video is 4K. Then this conventional video signal is electronically down-converted to HD. During the down conversion process an electronic low pass filter is then used to prevent aliasing and moiré in the newly created HD video. You can’t do this with raw sensor data as raw is BEFORE processing and derived directly from the sensor pixels, but you can do this with conventional video as the HD is derived from a fully processed 4K video signal.
I hope you understand this. It’s not an easy concept to understand and even harder to explain. I’d love your comments, especially anything that can add clarity to my explanation.
UPDATE: It has been pointed out that it should be possible to take the 4K bayer and from that use an image processor to produce a 2K anti-aliased raw signal.
The problem is that, yes in theory you can take a 4K signal from a bayer sensor into an image processor and from that create an anti-aliased 2K bayer signal. But the processing power needed to do this is incredible as we are looking at taking 16 bit linear sensor data and converting that to new 16 bit linear data. That means using DSP that has a massive bit depth with a big enough overhead to handle 16 bit in and 16 bit out. So as a minimum an extremely fast 24 bit DSP or possibly a 32 bit DSP working with 4K data in real time. This would have a big heat and power penalty and I suspect is completely impractical in a compact video camera like the F5/F55. This is rack-mount high power work station territory at the moment. Anyone that’s edited 4K raw will know how processor intensive it is trying to manipulate 16 bit 4K data.
When shooting HD your taking 4K 16 bit linear sensor data, but your only generating 10 bit HD log or gamma encoded data, so the processing overhead is tiny in comparison and a 16 bit DSP can quite happily handle this, in fact you could use a 14 bit DSP by discarding the two LSB’s as these would have little effect on the final 10 bit HD.
For the high speed modes I doubt there is any way to read out every pixel from sensor continously without something overheating. It’s probably not the sensor that would overheat but the DSP. The FS700 can actually do 120fps at 4K for 4 seconds, so clearly the sensor can be read in it’s entirety at 4K and 120fps, but my guess is that something gets too hot for extended shooting times.
So this means that somehow the data throughput has to be reduced. The easiest way to do this is to read adjacent pixel groups. This can be done during the readout by addressing multiple pixels together (binning). If done as I suggest in my article this adds a small degree of antialising. Sony have stated many times that they do not pixel or line skip and that ever pixel is used at 2K, but either way, whether you line skip or pixel bin the effective pixel pitch increases and so you must also change the OLPF to match.







